Doxa: Multi-Agent Reputational Analysis
Open-Source · 2026
An open-source multi-agent system that transforms a company name and a news window into a citation-audited reputational SWOT report. Predicted material events for Anthropic and Meta days before they became public knowledge.
View on GitHubContext
Reputational analysis typically means manually scanning news sources, reading for relevant signals, and synthesizing them into a structured view. For fast-moving situations, this is slow and incomplete. A single researcher can only read so many articles, and the coverage that gets missed is often the coverage that matters.
LLM-based summaries offer speed but introduce a different problem. When a model is asked to characterize a company's reputation without a grounded evidence corpus, it generates plausible-sounding claims with citations that may not exist. The output looks authoritative; the sourcing is unverifiable.
Problem
Two issues make this domain hard to automate reliably:
- Grounding. A system that synthesizes reputation from news must trace every claim to a real, retrieved article. Models operating in summarization mode hallucinate citations when given latitude to do so, and those errors are hard to catch without manual cross-reference.
- Structure. An unstructured reputation summary is useful but not actionable. A SWOT framework constrains the output to a taxonomy (strengths, weaknesses, opportunities, and threats) that is more useful to decision-makers and easier to validate.
Goal
A system that reads real-time news coverage about a company, classifies it according to a structured SWOT rubric, and produces findings backed exclusively by retrieved evidence, without hallucinated references.
Approach
I built Doxa as a sequential multi-agent pipeline where each stage has one well-defined responsibility and passes its output to the next.
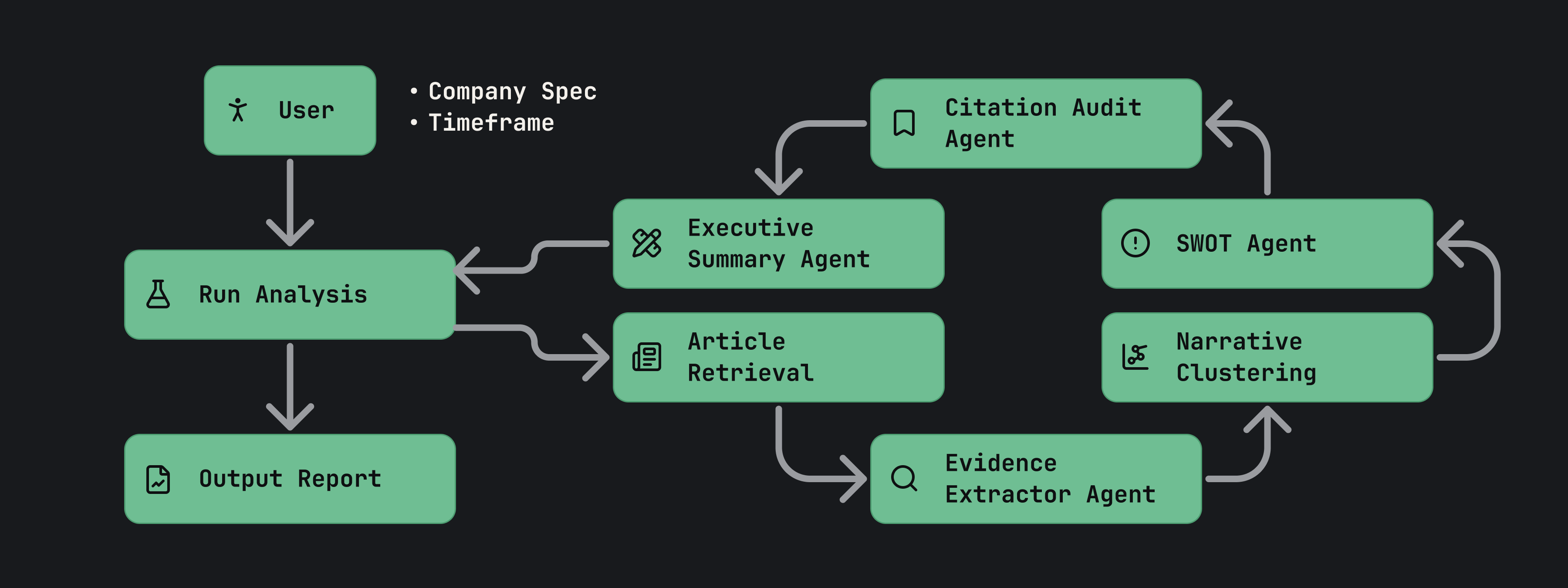
Evidence-first extraction
The pipeline begins by retrieving articles from a configurable news window, then running an Evidence Extractor agent that converts each article into structured, source-grounded claims. Claims are discrete factual statements, each pinned to the article that supports them. Semantically similar claims are then grouped into narrative clusters via embedding-based similarity before any SWOT classification occurs.
Citation-audited findings
The SWOT Assessor reads each narrative cluster and produces a scored finding for one of the four categories. Before a finding can enter the final report, a dedicated Citation Auditor agent independently cross-checks every finding against the retrieved claims corpus. If a claim cannot be verified against a real article, it is rejected and the Assessor must revise. This audit loop prevents hallucinated citations from reaching the output.
Iterative refinement
Rather than a single pass, the Assessor and Auditor participate in a bounded debate: the Auditor returns structured feedback, the Assessor revises, and the cycle repeats until all findings are grounded or the retry budget is exhausted.
Results
Doxa has been validated against two retroactive benchmarks, each targeting a real event within a specific news window:
- Anthropic, Fable/Mythos model release (June 2026). Doxa flagged the launch as a threat: "Safety concerns from Mythos vulnerabilities and document modifications." Four days after the analysis window closed, the US Government ordered Anthropic to suspend Fable 5 and Mythos 5 access.
- Meta, AI training mandate (April 2026). Doxa identified an internal employee monitoring program as a weakness: "Internal employee monitoring for AI training raises privacy concerns." During the week of June 23, Meta halted the practice due to the same concerns.
![[Placeholder GIF: Scrolling through a Doxa HTML report, executive summary at the top, then the SWOT findings grid with inline evidence citations, then the full article appendix at the bottom]](/case-studies/doxa-report-summary.png)
Retrospective
The most important design decision was building the citation audit as a separate agent rather than relying on the Assessor to self-verify. An agent asked to both generate and validate its own findings will rationalize rather than reject. Separating those roles, having one agent who writes, and a different agent who challenges, is what kept the output factual. Without a dedicated audit loop, the hallucination rate was not acceptible for a research tool.
Tech Stack
| Languages | Python |
| Tools | OpenAI SDK, Pydantic, SQLite |
| Data | World News API |